빈도분석
in Notes / Dataanalytics / R / R Programming Language
Another widely used data structure for data analyzing
빈도분석 I
정규분포
- 모든 통계기법의 시초,
random 세계 (random sampling)에서만 관찰 (자연스러운 현상에서만 관찰 가능) - 모수통계: 정규분포 가정 만족 데이터에 가정 (아닐 시 비모수통계)
벤포드 법칙 (Benford’s Law)
- aka 첫자리 숫자의 법칙: 실생활에서 관찰되는 수치를 첫 자리 숫자에 따라 분류 시 첫 자리 숫자가 커질수록 그 분포가 점차 감소되는 현상
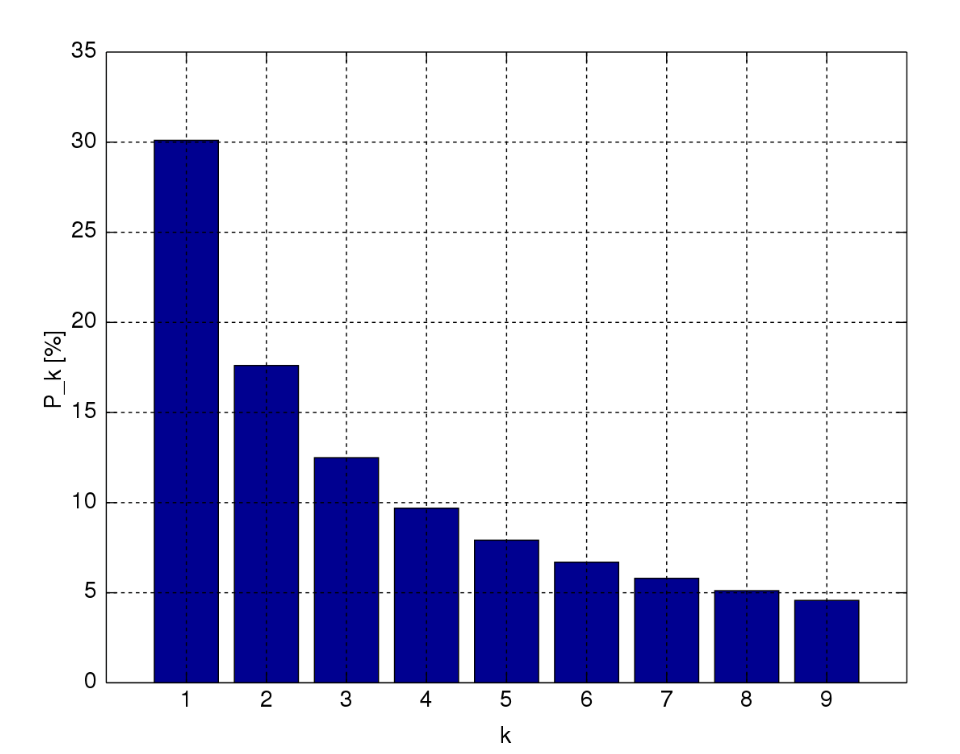
- 자연적인 현상에서만 발생가능
- 고로 표본이 자연적인 현상에서 발생하였는지에 대한 기준점이 될 수 있다 (왜인지는 안 밝혀짐)
- 응용:
- 수학적 예측 모형: 미래의 주가지수, 인구통계 예측
- 컴퓨터 설계 분야: 컴퓨터의 계산속도 향상
- 회계 분야: 부정 회계 또는 인위적 조작 자료의 탐지 (인위적 데이터 탐지)
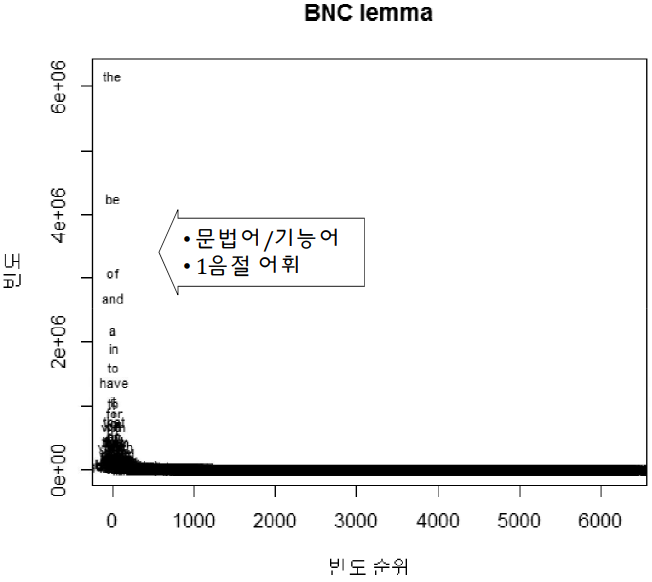
Zipf 법칙
- 하버드대의 독문학과 교수로 어휘 빈도와 빈도 분포의 불균형 관심 (어휘 + 수량화)
- 어휘 순위와 빈도수는 반비례 관계의 규칙성
- 로그-로그 척도 (log-log scale) 기울기 -1과 유사 (멱법칙 power law)
- 보편성: 어휘 빈도뿐만 아닌 빈도로 기술되는 자연, 사회 현상에도 관찰
-
80:20 법칙 , 파레토 법칙, long-tail 법칙으로도 알려져 있다
- (소수독점의 원리, 20% of the population holds 80% of the money)
- 법칙의 원인 규명 실패
LNRE (Large Number of Rare Events)
- Zipf의 연장모델, 저빈도에 집중하다 (long tail)
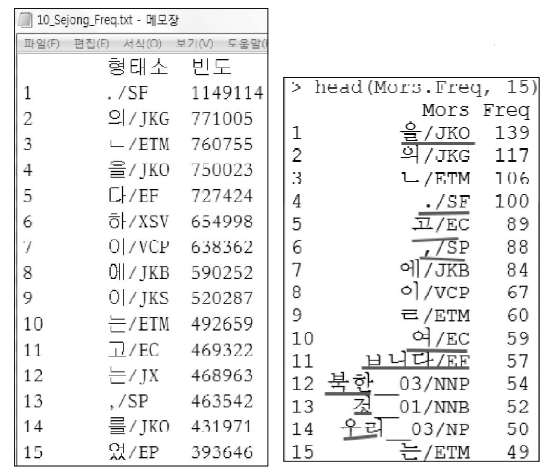
| 빈도수 | BNC (British National Corups) | 세종 형태분석 말뭉치 |
|---|---|---|
| 3 이하 | 66% | 46% |
| 1 | 69.21% | 49.21% |
➜ 이렇게나 많은 단어들을 무시하고 분석을 했었다
Zipf 법칙과 LNRE모형의 의미
- Zipf 법칙 ➜ 고빈도 어휘는 소수, 대부분 기능어/문법어
LNRE 모형 ➜ 저빈도 어휘가 대다수
- 마치 역사를 소수의 왕족과 귀족의 역사로 볼 것인가 or 대다수의 민중의 역사로 볼 것인가
빈도분석 II
연습문제
- 10_PresidentialSpeech2016_UTF-8.txt.tag 로 형태소 단위 벡터 Mors 만들기
답:
MORS <- scan(file="10_PresidentialSpeech2016_UTF-8.txt.tag", what="char", quote=NULL, encoding="UTF-8") Mors <- unlist(strsplit(MORS, '[+]')) 변수 Mors에 대해 Mors.Freq 생성 (빈도표 추출, 내림차순 정렬, 데이터프레임 생성)
답:
tMors <- sort(table(Mors), decreasing = T) Mors.Freq <- data.frame(Mors = rownames(tMors), Freq = as.vector(tMors))- 변수 Mors.Freq에 대해 일반명사 (/NNG), 고유명사 (/NNP), 동사 (/VV), 형용사(/VA), 일반부사 (/MAG)만으로 구성되는 CNT.Freq 생성
답:
CNT.Freq <- Mors.Freq[grep( '(/NNG|/NNP|/VV|/VA|/MAG)', Mors.Freq$Mors), ] - CNT.Freq의 워드클라우드 생성
답:
library(wordcloud) wordcloud(CNT.Freq$Mors, CNT.Freq$Freq, scale=c(3,0.8), min.freq = 2, max.words=90, random.order=F, rot.per=0.4, color=brewer.pal(8, "Dark2"))
살펴보기
참고코퍼스 (세종 형태분석 코퍼스)와 비교
문장이 길어질 수 있다
| 형태소 | 세종 형태분석 코퍼스 | CNT.Freq | 비고 |
|---|---|---|---|
| . | 1위 | 5위 | 마침표가 자주 안 나옴 |
| , | 13위 | 6위 | 쉼표가 잦다 ➜ 문장이 잘 안 끝남 |
| 고 | 11위 | 5위 | 문장이 자주 이어짐 |
- 등 비교를 통해 해당 코퍼스의 특성을 보다 깊이 알아낼 수 있다
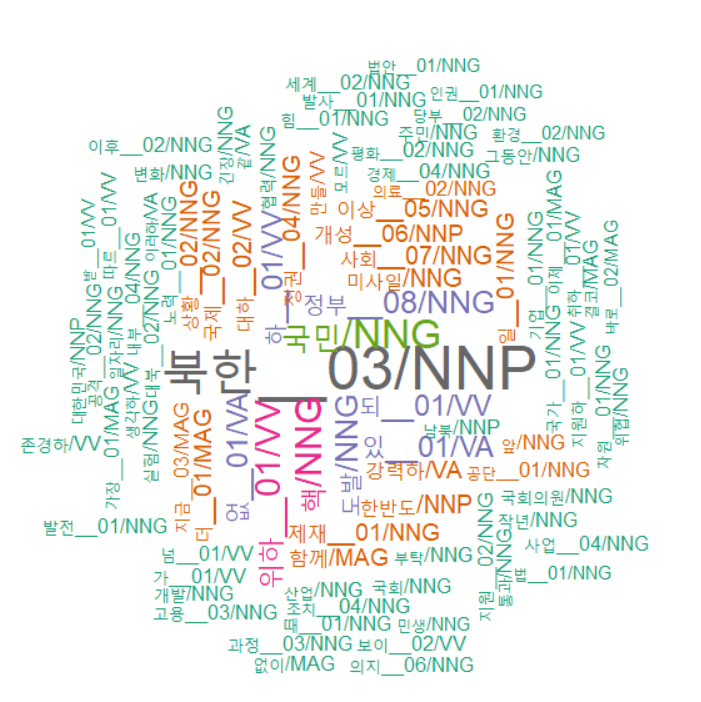
- 북한 관련어 (북한, 핵, 도발, 정권, 미사일, 한반도…등등)
경제 관련어 (경제, 일자리, 지원하, 기업, 협력…등)
➜ 더욱 심도있는 분석을 위해서는 관련 분야의 지식이 필수적이다- 데이터와 통계의 역할과 연구자의 역할
데이터가 어떤 이야기를 알아서 들려줄 것이라는 생각은 버리는 편이 좋다…통찰은 오직 사람만이 할 수 있는 능력이다…데이터를 보는 사람의 역량은 더욱 강조되어야 한다.
-송길영 (2015) 상상하지 말라: 그들이 말하지 않는 진짜 욕망을 보는 법, 북스톤.
연습문제
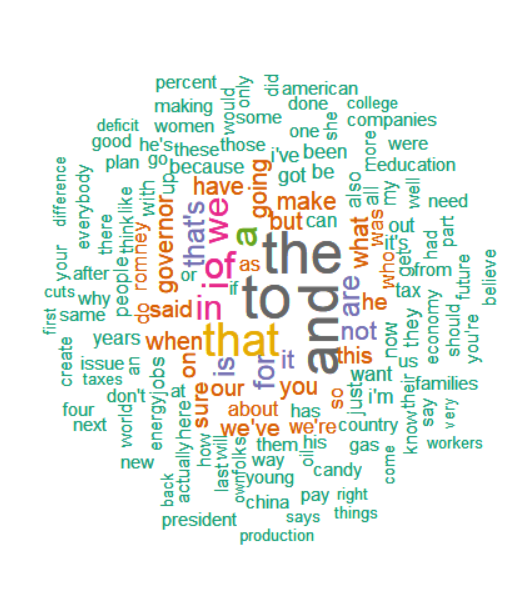
- 10_Obama.txt 어휘단위 벡터로 불러오고 소문자 변환, () 안의 지문 제거 뒤 어휘 앞뒤 문장부호 연쇄제거, 벡터의 원소 중 빈문자열 제거 후 변수명 TEXT로 저장 (순서 준수)
답:
TEXT <- scan(file = '10_Obama.txt', what="char", quote=NULL) text <- tolower(TEXT) TEXT <- gsub('[(]+.?[)]', '', text) TEXT <- gsub('^[[:punct:]]+|[[:punct:]]+$', '', TEXT) TEXT <- TEXT[nchar(TEXT) > 0] - TEXT에 대해 빈도표 추출 후 빈도 내림차순 정렬, 데이터프레임으로 변환 (TEXT = 어휘, Freq = 빈도)
답:
text <- sort(table(TEXT), decreasing = T) TEXT.Freq <- data.frame(TEXT = rownames(text), Freq = as.vector(text)) - TEXT.Freq 이용하여 워드클라우드 생성
답:
library(wordcloud) wordcloud(TEXT.Freq$TEXT, TEXT.Freq$Freq, scale=c(3,0.8), min.freq = 2, max.words=150, random.order=F, rot.per=0.4, color=brewer.pal(8, "Dark2"))