Text Analysis
in Notes / Dataanalytics / Dataanalyticsbasics
01/15/23
Text Analysis
- Morphology Analaysis through Twitter data with ratings
import pandas as pd
survey = pd.read_csv('survey.csv')
Survey
| # | datetime | comment | satisfaction |
|---|---|---|---|
| 0 | 2019-03-11 | 역앞에 젊은이들이 모여있다(AA역) | 1 |
| 1 | 2019-02-25 | 운동할 수 있는 장소가 있는 것이 좋다 | 5 |
| 2 | 2019-02-18 | 육아 지원이 좋다 | 5 |
| 3 | 2019-04-09 | 어린이집에 바로 입원할 수 있다(대기아동 없음) | 4 |
| 4 | 2019-01-06 | 역앞 상가가 쓸쓸하다 | 2 |
| … | … | … | … |
| 81 | 2019-01-21 | 초등학교 운동장이 잔디밭이라서 아주 좋다 | 5 |
| 82 | 2019-04-30 | 홈페이지에서도 설문지를 투고할 수 있게 해 달라 | 2 |
| 83 | 2019-01-09 | 공원에 놀이기구가 너무 적다 | 1 |
| 84 | 2019-03-09 | 공원을 더 늘렸으면 좋겠다 | 2 |
| 85 | 2019-04-02 | 역앞에 주차장이 적다, 불편하다 | 1 |
- 86 rows × 3 columns
survey.isna().sum()
| datetime | 0 |
| comment | 2 |
| satisfaction | 0 |
| dtype: | int64 |
survey = survey.dropna()
survey.comment.value_counts()
Output
- 봄의 벚꽃길이 최고로 아름답습니다.벚꽃길을 더 늘려줬으면 좋겠다 1
- 이상한 아저씨가 말을 걸어온 적이 있다.경찰 순찰을 더 강화해 주길 바란다 1
- 데이트 명소를 갖고 싶다 1
- 급행이 멈춰서 시내에 나가기 쉽고 좋다 1
- 관공서 출장소를 역전에 지어 주었으면 한다 1 ..
- 도둑고양이 피해가 심각하다, 도둑고양이 대책은? 1
- 공원에 놀이기구가 너무 적다 1
- 최근 지방 넘버의 차가 많다, 치안은 제대로 되어 있는가? 1
- 지난달 직원 비리의혹에 대해 좀 더 자세히 설명해 달라 1
버스가 별로 안 온다 1
- Name: comment, Length: 84, dtype: int64
# delete 'AA'
survey['comment'] = survey['comment'].str.replace('AA',"")
# delete special characters
survey['comment'] = survey['comment'].str.replace('\(.+?\)',"")
# add 'length' column to dataframe
survey['length'] = survey['comment'].str.len()
Survey
| # | datetime | comment | satisfaction | length |
|---|---|---|---|---|
| 0 | 2019-03-11 | 역앞에 젊은이들이 모여있다 | 1 | 14 |
| 1 | 2019-02-25 | 운동할 수 있는 장소가 있는 것이 좋다 | 5 | 23 |
| 2 | 2019-02-18 | 육아 지원이 좋다 | 5 | 9 |
| 3 | 2019-04-09 | 어린이집에 바로 입원할 수 있다 | 4 | 17 |
| 4 | 2019-01-06 | 역앞 상가가 쓸쓸하다 | 2 | 11 |
| … | … | … | … | … |
| 81 | 2019-01-21 | 초등학교 운동장이 잔디밭이라서 아주 좋다 | 5 | 22 |
| 82 | 2019-04-30 | 홈페이지에서도 설문지를 투고할 수 있게 해 달라 | 2 | 26 |
| 83 | 2019-01-09 | 공원에 놀이기구가 너무 적다 | 1 | 5 |
| 84 | 2019-03-09 | 공원을 더 늘렸으면 좋겠다 | 2 | 14 |
| 85 | 2019-04-02 | 역앞에 주차장이 적다, 불편하다 | 1 | 17 |
- 84 rows × 4 columns
import matplotlib.pyplot as plt
%matplotlib inline
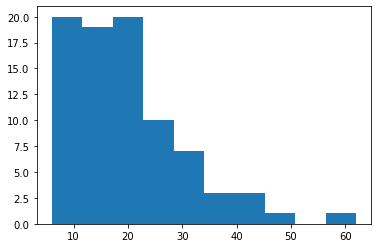
plt.hist(survey['length'])
Output
(array([20., 19., 20., 10., 7., 3., 3., 1., 0., 1.]),
array([ 6. , 11.6, 17.2, 22.8, 28.4, 34. , 39.6, 45.2, 50.8, 56.4, 62. ]),
<a list of 10 Patch objects>)
survey.describe()
Output
| satisfaction | length | |
|---|---|---|
| count | 86.000000 | 84.000000 |
| mean | 2.616279 | 19.880952 |
| std | 1.448477 | 10.422872 |
| min | 1.000000 | 6.000000 |
| 25% | 1.000000 | 12.000000 |
| 50% | 2.000000 | 19.000000 |
| 75% | 4.000000 | 24.000000 |
| max | 5.000000 | 62.000000 |
- 84 rows × 4 columns
형태소 분석 진행
Installing koNLPy
- Installing in Jupiter Notebook
- anaconda prompt: (when JAVA_HOME is already set)
conda update pip conda update conda conda install -c conda-forge jpype1 pip install konlpy
- anaconda prompt: (when JAVA_HOME is already set)
- Installing in my PC
from konlpy.tag import Twitter
twt = Twitter()
text = '이것저것 설치할게 참 많네요...화이팅!'
tagging = twt.pos(text)
tagging
[('이', 'Determiner'),
('것', 'Noun'),
('저', 'Determiner'),
('것', 'Noun'),
('설치', 'Noun'),
('할게', 'Verb'),
('참', 'Verb'),
('많네요', 'Adjective'),
('...', 'Punctuation'),
('화이팅', 'Noun'),
('!', 'Punctuation')]
all_words = []
parts = ['Noun']
for n in range(len(survey)):
# text = each comment (either boolean or string due to regex sth..)
text = survey['comment'].iloc[n]
if type(text) == str:
# words = comment 형태소 분석
words = twt.pos(text)
words_arr = []
for i in words:
if i =='EOS'or i=="": continue
word_tmp =i[0]
part = i[1]
if not (part in parts):continue # if not one of 'parts', pass
words_arr.append(word_tmp) # else, append that word
all_words.extend(words_arr)
print(all_words)
Output
['역앞', '젊은이', '운동', '수', '장소', '것', '육아', '지원이', '어린이집', '바로', '입원', '수', '역앞', '상가', '생활', '놀', '장소', '놀', '장소', '상업시설', '좀', '더', '병원', '사이클링', '코스', '축제', '좀', '더', '성대', '초등학교', '공원', '더', '근처', '공원', '살기', '슈퍼', '육아', '데이트', '명소', '상가', '좀', '더', '밤길', '쓰레기', '처리', '영화관', '가로수', '더', '공원', '추가', '관광', '명소', '육아', '최고', '길이', '시내', '접근성', '집세', '합리', '의', '교통', '체증', '게', '해', '상가', '지붕', '비', '큰일', '상가', '더', '카페', '스포츠', '센터', '자주', '이용', '스포츠', '센터', '이용', '요금', '워킹맘', '지원', '더', '버스', '별로', '안', '자전거', '달리기', '달리기', '운동', '수', '장소', '기업', '역앞', '주차장', '아저씨', '말', '적', '경찰', '순찰', '더', '소방', '활동', '수', '재난', '시', '피난', '장소', '것', '요즘', '강', '범람', '피해', '크게', '이', '도시', '범람', '방지', '취하', '설명', '신호등', '사거리', '때문', '사고', '신호', '상가', '활성화', '활동', '좀더', '행정', '뒷받침', '아이', '놀', '장소', '역앞', '자전거', '주차장', '가로수', '낙엽', '청소', '가로수', '재해', '시', '비축', '상황', '보도', '길이', '수', '지역', '자치', '단체', '더', '지원', '자치', '단체', '활동', '안심', '살', '수', '관광지', '최근', '지방', '넘버', '치안', '제대로', '주차장', '수가', '요금', '역', '앞', '공공', '주차장', '보행자', '용', '신호', '노인', '어린이', '생각', '설정', '급행', '시내', '버스', '노선', '봄', '벚꽃', '길이', '최고', '벚꽃', '길', '더', '옆', '동네', '쓰레기', '처리', '시설', '걱정', '공해', '시장', '활기', '앙케이트', '제대로', '확인', '거리', '조성', '반영', '자세', '지난달', '직원', '비리', '의혹', '대해', '좀', '더', '설명', '달라', '시청', '담당자', '마음', '관공서', '출장소', '역전', '관공서', '토요일', '일요일', '재', '피난', '경로', '좀', '더', '표시', '시', '홈페이지', '관공서', '연결', '대응', '더', '시오', '골목', '동물원', '겨울철', '노면', '동결', '사고', '처리', '자연', '경관', '도둑고양이', '피해', '도둑고양이', '대책', '관공서', '상담', '때', '매우', '대해', '고속도로', '길이', '정체', '확장', '시', '마스코트', '걸', '야간', '병원', '불안', '고령자', '지원', '시설', '초등학교', '운동장', '잔디밭', '아주', '홈페이지', '설문지', '투고', '수', '해', '달라', '공원', '놀이기구', '공원', '더', '역앞', '주차장']
# New DataFrame
all_words_df =pd.DataFrame({'words':all_words, 'count':len(all_words)*[1]})
all_words_df
| |words|count| |:-:|:—:|:—:| |0| 역앞 |1 | |1| 젊은이 |1| |2| 운동| 1| |3| 수 |1| |4| 장소 |1| |…| … |…| |278| 놀이기구 |1| |279| 공원 |1| |280| 더 |1| |281| 역앞 |1| |282| 주차장 |1|
- 283 rows × 2 columns
all_words_df.groupby('words').sum()
Output
| words | count| |:—–:|:—-:| | 가로수| 3| | 강 | 1| | 거리 | 1| | 걱정 | 1| | 걸 | 1| | … | …| | 확인 | 1| | 확장 | 1| | 활기 | 1| | 활동 | 3| | 활성화 | 1|
- 187 rows × 1 columns
all_words_df = all_words_df.groupby('words').sum()
all_words_df.sort_values('count',ascending= False)
Output
| words | count| |:—–:|:—-:| |더 |14| |수 |7| |장소| 6| |주차장 |5| |좀 |5| |… |…| |상황 |1| |생각 |1| |생활 |1| |설문지 |1| |활성화 |1|
- 187 rows × 1 columns