Chapter 6 - Foundations of Business Intelligence - Databases and Information Management
in Notes / Othermajors / Managementinformationsystems
- 1: Organizing Data in a Traditional File Environment
- 2: Database Approach to Data Management
- 3: Using DB to improve Business Performance and Decision Making
- 4: Managing Data Resources
1: Organizing Data in a Traditional File Environment
- 파일 시대: 실제로 데이터를 (물리적) 파일로 차곡차곡 모아서 정리하던 시대
Data Hierarchy :
순서는 올라갈수록 중요함

Bit: B inary dig itByte: 8 bits- entity (객체) : 데이터베이스로 만들어서 저장/관리하고 싶은 대상물
- 사람, 수업, 제품 …등등 다 됨
- attribute (속성)
파일 관리의 문제점:
-
Data Redudancy : 데이터가 중복됨
-
Data Inconsistency : 데이터의 비일관성
- Program-Data Dependance: 일하는 곳에 데이터가 따라가야함 (불편 -> 비효율 발생) - program: 데이터 가지고 하는 일
- Lack of Flexibility (유연성 떨어짐)
- Poor Security (보안성 빈약)
- Lack of Data Sharing and Availability (데이터 공유와 가용성)
2: Database Approach to Data Management
- DBMS: SW, 위 문제점들 (1~6) 해결
Relational DBMS
- 관계형 데이터베이스 관리시스템, 가장 상용화된 DBMS
- MySql (오픈소스), Access (MS) 등등
- 테이블 형태의
- columns (attributes, fields)
- rows (records, tuples)
- Primary Key (PK): 기본키, 레코드를 구별할 수 있는 key
- Foreign Key: 외래키
- RDBMS 연산 (Operations)
- Select (\(\sigma\))
- Join (\(\bowtie\))
- Project (\(\pi\))
Capabilities of DBMS
- Data Definition: 데이터 정의
Data Dictionary: 데이터에 대한 정보를 저장해두는 파일
- Data Manipulation Language
DML(조작언어)insertaddupdatechangedelete,wipeselect, retrieveSELECT X FROM Y WHERE X.x = Z
- Structured Query Language
SQL: 구조적 질의 (query) 언어- DB 표준언어 by IBM
- reporting : 데이터베이스 가지고 양식 만들어줌
- Crystal Reports 자주 사용된다
Designing Databases
- Normalization : 정규화
비정규형으로 normal form: 정규형으로 바꾸는 작업 - 가장 효율적으로 정규화해서 쉽게 사용
- n차 정규화…3차만 해도 잘 됨
- Referential Integrity 참조 무결성:
- 참조할때 실패가 일어나서는 안된다 (외래키 무조건 존재)
- 참조 무결성을 위해 주로 데이터를 삭제하진 않고 attribute하나를 더 만들어서
deletedAt등을 관리한다
- entity-relationship diagram (ERD) 객체 관계도면:
- 1 대 다, 1대 1 관계 등을 표기
- No_Sql: Not Only Sql (No Sql 아님!!)
- SQl로만 처리 불가능한 data 유형이 많아졌기 때문.
-
csv, xml, json...etc
- Cloud Databases: No-sql 저장하기 좋음
-
AWS
-
Blockchain
- 중개 및 수수료 없다는 장점
- Bitcoin: 블록체인으로 만듦
- 탈중앙화 (decentralized) 계약서의 분산화 \(\longrightarrow\) 안정성 증가
- 수정 불가, 재입력시 재입력했다고 같이 추가됨
- 보상체계: 마이닝 (채굴), 규칙에 맞는 숫자를 채굴해낸다.
- Smart Contract : 위조, 변조 불가
3: Using DB to improve Business Performance and Decision Making
-
3V of Big Data
- Volume 규모
- Variety 종류
- Velocity 속도
- +Value 가치
- In-Memory Computing (IMC): main memory (RAM) 사용해서 data store 함
- memory (기억장치) : 주로 작지만 빠름
- storage (저장장치) : 매우 크지만 (1테라까지) fetch하는데 보다 늦음
- Virtual Memory (가상 메모리): 램이 부족해서 하드디스크를 RAM처럼 활용하는 기법
- Data Warehouse (DW): 데이터 창고
- 기업 곳곳에 (내외부) 흩어져 있는 (산재, spread) 각종 유형의 데이터들을 한 군데에 모아둔 대규모 워크스페이스
- not 개인 (employee)수준, BUT 기업 수준(enterprise level)
- aka DB
Data warehousing : 관리 기법
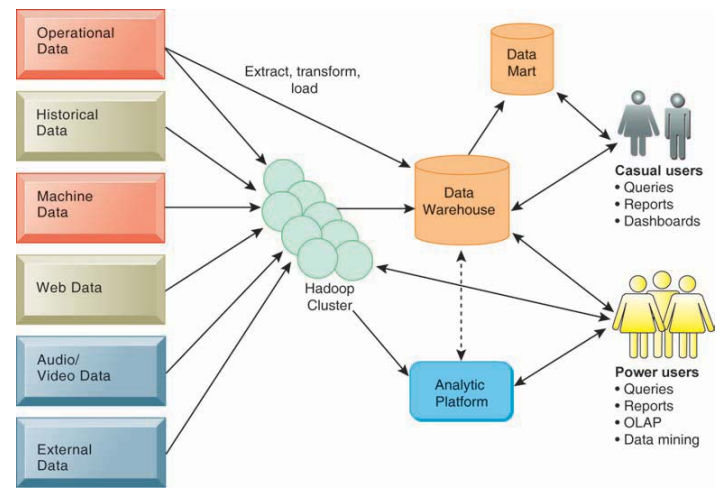
- 왼쪽: 분산된 data
- Hadoop Cluster : (Apache Hadoop) 빅데이터를 관리하는 기법, opensource
- 분산형으로 저장되는 것이 특징
- Data Warehouse: 잘 정돈된, 규격화된 데이터
- Data Mart: DW의 부분집합, DW의 가장 중요한, 또는 요약본 저장
- Data Lake (사진에 없음): 선 때려넣고 후 분리수거 하는 느낌, 모든 raw data (가공되지 않은) 보유
- Extract, transform, load (fetch) (ETL): 분류의 기준과 규칙에 의해서 정리하는 과정 (like 분리수거)
- Data warehouse를 사용하기 위해서는 꼭 필요함
- Power users can also additionally use OLAP and Data mining
- Online Analytical Processing (OLAP) : 데이터 분석 처리
- OLTP :데이터 거래 (transaction) 처리
- Online: 실시간으로 처리한다는 뜻
- OLAP의 특성: n-D 처리 가능
- Data Cube (3D data) \(\rightarrow\) 수작업 불가능, 컴퓨터 필요
- 가장 유명한 프로그램: 엑셀의 pivot table
- Data Mining : aka Pattern Recognition
- 데이터간의 관계 (relationships)
- 데이터의 간의 패턴 (patterns)
- 데이터의 앞으로 나갈 관계 수행 추세 (trends)
Knowledge Discovery in DB (KDB): 데이터베이스에서 지식을 발견한다 (Data Mining의 다른 이름)
데이터 마이닝 기법 (의사 결정을 위한)
- Associations (연산, 연결 기법): 가장 대표적, 연관성 분석 및 예측
CROSS_SELLING: 기저귀와 맥주를 같이 전시해두면 기저귀를 사러 온 사람들이 맥주도 사가기에 소비효과를 기대할 수 있음 (단, 매장에 머무는 시간을 짧을테니 tradeoff) - Sequences (순차, 순서): Associations + 시간 개념 (일정 시간 지난 다음)
UPSELLING: n년 뒤 더 업그레이드 된 차 추천 - Classification (분류법) : 분류기준이 정해져 있음 \(rightarrow\) 그에 맞게 카테고리로 나눔 (지도학습)
- RFT 분석 (Recency (최근), Frequency, Monitory (금액적)) : 우수 고객 선정 법
- Clustering (군집법) : 분류기준이 없음, 나눠보면서 찾는 것 (데이터의 특성을 반영, AI의 비지도 학습)
- Forecasting : 데이터만을 보고 예측, 추론
- Associations (연산, 연결 기법): 가장 대표적, 연관성 분석 및 예측
- Text Mining (Web mining) : 데이터 중 텍스트 데이터를 가지고 마이닝
- Sentiment Analysis (감정 분석) : positive / negative / netural 분석
- 100% 신뢰 불가
- Sentiment Analysis (감정 분석) : positive / negative / netural 분석
- Databases and the Web \(Client \longleftrightarrow Web\hspace{0.1cm} Server \longleftrightarrow Application \hspace{0.1cm} Server\longleftrightarrow Database \hspace{0.1cm} Server\longleftrightarrow Database\)
4: Managing Data Resources
- 관리자들이 데이터를 다룰때 갖춰야 할 태도
- Data Governance: 데이터의 의미와 체계를 운영 시 정확히 알고 있어야 함
- Governance: 전략가 수준의, 실무자들의
- Data Quality:
- gigo: Garbage In Garbage Out
- Data Cleaning (aka Scrubbing)
- 퀄리티를 유지하기 위해서는 Data Cleansing이 잘 필요한데, 비용이 만만치 않다
- 해결법: 최초 입력 시 자동화로 입력 (실수는 현저히 줄어듦)
- Review Questions