N-Gram
Another widely used data structure for data analyzing
N-Gram I : N-gram과 맥락
연습문제
- 연습문제 #1:
- 10_PresidentialSpeech2016_UTF-8.txt.tag 불러오기 (UTF-9)
- Mors 빈도표 추출 (내림차순 정렬)
- Mors.Freq 내림차순 변환 (형태소를 Mors 칼럼으로)
답
file <- scan(file = "10_PresidentialSpeech2016_UTF-8.txt.tag", what="char", quote=NULL, encoding="UTF-8") Mors <- unlist(strsplit(file, "[+ ]")) tab <- sort( table(Mors), decreasing = T ) Mors.Freq <- data.frame( Mors = rownames(tab), Freq = as.vector(tab)) head( Mors.Freq )
- 연습문제 #2:
- “을/JKO” 또는 “를/JKO” 로 bigram (선행, pre.bi.Freq 생성)
- bigram (후행, post.bi.Freq 생성)
답
index <- grep("을/JKO|를/JKO", Mors) pre <- paste(Mors[index-1], Mors[index]) pre.tab <- sort( table(pre), decreasing = T ) pre.Freq <- data.frame( pre.bi.grams = rownames(pre.tab), Freq = as.vector(pre.tab)) post <- paste(Mors[index], Mors[index+1], sep=" ") post.tab <- sort( table(post), decreasing = T ) post.Freq <- data.frame( post.bi.grams= rownames(post.tab), Freq = as.vector(post.tab))
- 연습문제 #3:
- “을/JKO” 또는 “를/JKO” 로 trigram (앞뒤 선행, 후행, tri.Freq 생성)
답
index <- grep("을/JKO|를/JKO", Mors) tri <- paste(Mors[index-1], Mors[index], Mors[index+1], sep=" ") tri.tab <- sort( table(tri), decreasing = T ) tri.Freq <- data.frame( tri.grams= rownames(tri.tab), Freq = as.vector(tri.tab))
N-Gram
빈도분석의 한계
- 빈도목록은 타입과 토큰수의 쌍으로 구성
- 타입 : 어휘+형태소, 형태적으로 동일하면 동일 타입으로 처리
- (ex: us: 인친대명사 us와 미국 us)
- 맥락이 제거 ➜ 정확한 의미 파악 에 한계
- 맥락을 살펴볼 수 있는 분석:
- 용례 분석 (concordance)
- N-gram
- 한국의 경우 겨우 조사 붙는 수준임
- 연어분석 (collocation) ➜ 단어 간 거리 분석가가 지정가능, 더 포괄적
- Ngram : 문법적
- 연어분석: 사회적, 의미적, 인지적, 문화적
- N-Gram:
- Uni-Gram : 하나의 어휘가 하나의 분석 단위, 맥락이 사라지기 때문에 일반적으로 분석 가치가 없음
- Bi-Gram : ‘을/를’로 분석하는 것은 일반적으로 비효과적
- 단, 목적격 조사를 통해 지향점에 대해 알 수 있다
- 많다고 무조건 효과적이지는 않으나 적은 경우 분석할만한 사이즈가 안되는 경우가 대다수 (ex: Zipf의 법칙은 작은 파일에 실용불가)
- 예외는 항상 있다 (효과적이지 못하다고 알려진 분석기법들이 때에 따라 가장 적절한 방법일 때도 있다)
- 한가지 데이터에 대해 여러 다른 분석기법을 활용하는 이유: 관점(기법)에 따라 얻는 것이 다르기 때문
좋은 기법 이란 난이도에 따르는 것이 아닌 파악하고자 한 정보를 손에 쥐어주는 기법이다- 연습문제 #4:
- 10_Obama.txt에 대해 어휘 단위 파일로 불러와서 소문자 변환
- () 안의 지문 제거
- 어휘 앞뒤 문장부호 연쇄제거
- 벡터의 원소 중 빈문자열 제거
- bi-gram만들기
- bi-gram 빈도 데이터프레임 만들기
- bi-gram 워드클라우드 생성
답
text <- tolower(TEXT) text <- gsub('[(].+?[)]', '', text) text <- gsub('^[[:punct:]]+|[[:punct:]]+$', '', text) text <- text[nchar(text) > 0] bigram <- paste(text[1:length(text)-1], text[2:length(text)], sep =" ") bigram.Freq <- data.frame(row.names=rownames(bigram), Freq=as.vector(bigram)) library(wordcloud) wordcloud(rownames(bigram.Freq), bigram.Freq$Freq, scale=c(3,0,0), min.freq=1, max.words=200, random.order=F, rot.per=0.4, color=brewer.pal(8, "Dark2"))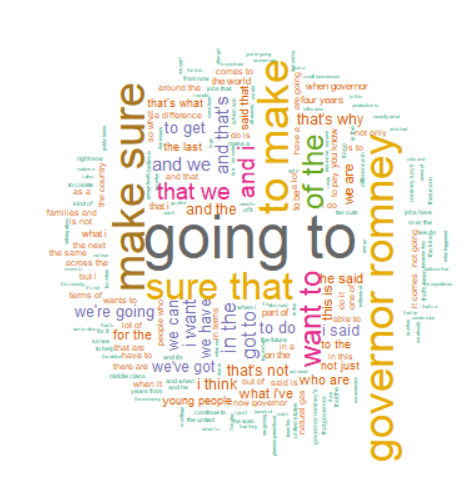
- 어휘와 어휘군에 대한 빈도는 인간의 기억에서 연결강도, 저장, 검색 관련 Kirsner(1994)
- 반복적으로 함께 나타나는 어휘를 경험하게 되면 인간은 언어적 패턴과 구문을 암묵적으로 학습함
- 빈번한 어휘단위의 노출은 인지적으로 처리가 빠르다 Bybee & Hopper(2001)
- 언어의 능숙도를 향상 ➜ 암묵적으로 습득
- 명시적 언어 지식에 집중
N-Gram II : 분포가설과 연어
친숙성 효과 (Familiarity Effect)
- 사용빈도가 높은 어휘일수록 (친숙한 어휘) 뇌에서 더 빨리 처리
- 어휘 판단 (lexical decision) 실험 : 언어음/문자열 연쇄 제시 후 어휘인지 아닌지 판단 실험
- 반응시간 (response time) 측정 ➜ 반응 시간이 오래 걸릴수록 다른 인지적 과제 수행 가정
- 사용 빈도가 높을수록 반응 시간이 빠르다
촉발 효과 (Priming Effect)
- 어휘 판단 실험에서 어떤 어휘 제시 후 형식적 또는 의미적으로 관련된 어휘 제시 시 반응 시간 빨라짐
의미적 ex) nurse 제시 후 flower보다 doctor의 반응시간이 빠름
형식적 ex2) “Mouse ate the cheese.”
- mouse = [ 쥐, 컴퓨터 마우스 ]
- cup보다 의미적 연관성이 높은 cat의 반응시간이 빠르다
- 형식적으로 관련되어 있는 computer의 반응시간도 빠르다
분포 가설 (distributional hypothesis)
Words that are used and occur in the same contexts tend to purport similar meanings.
(Harris, Z. (1954). “Distributional structure”)
A word is characterized by the comapany it keeps.
(Firth, J.R. (1957). “A synopsis of linguistic theory..”)
연어 collocation / collocates
- 친숙성/빈도 효과, 촉발효과 ➜ 동일 문장/문단/맥락에서 빈번하게 함께 사용되는 두 어휘쌍
- ex) cow & milk
- 연어의 활용
- 머릿속 사전 (mental lexicon)에서 어휘를 어떻게 저장, 검색하는가
통계적 연어
: 공기 (co-occurence) 어휘 중 관찰 빈도가 기대빈도보다 높은 어휘쌍
- 연어 추출 범위: 초창기에는 좌우 +- 4어휘였으나 현재는 자율적으로 연구자의 판단에 따라 추출
- 공식: t-score, MI (Mutual Information), Chi-Squared, log likelihood..
- 통계적 연어 추출 방법
- 공기어 추출 (연구대상이 되는 검색어/중심어(node)를 중심으로 좌우 몇 어휘 구간 내(span)에 함께 분포하는 모든 공기어 추출)
- 공기어 빈도 목록 추출
- 연어 계산: 공기어 빈도 목록에서 두 어휘의 공기빈도가 통계적 기대빈도보다 높은 어휘쌍 추출
- 유의미하다고 판된되는 공기어를 연어로 연구자가 분석
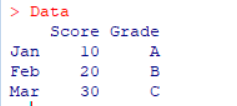
참고내용: 행 단위 데이터프레임 입력
Data <- data.frame(Score=vector(), Grade=vector()) for ( i in 1:3){ Data[i, ] <- c( i*10, LETTERS[i]) rownames(Data)[i] <- month.abb[i] }
lapply
lapply( 벡터, 함수 ) => 리스트 출력
> a <- seq(2, 10, 3)
> a
[1] 2 5 8
> lapply( a, function(i){c((i-3):(i-1), (i+1):(i+3))})
[[1]]
[1] -1 0 1 3 4 5
[[2]]
[1] 2 3 4 6 7 8
[[3]]
[1] 5 6 7 9 10 11
> b <- unlist(lapply( a, function(i){c((i-3):(i-1), (i+1):(i+3))}))
> b
[1] -1 0 1 3 4 5 2 3 4 6 7 8 5 6 7 9 10 11
sapply
sapply( 벡터, 함수 ) => matrix 출력
class(a)
[1] "matrix" "array"
> a <- sapply(names(Freq.span)[1:5], function(x){ c(Freq.all[x], Freq.span[x]) })
> a
고/EC 의/JKG ㄴ/ETM 여/EC ,/SP
고/EC 89 117 106 59 88
고/EC 54 51 43 37 35
> t(a) #transpose
고/EC 고/EC
고/EC 89 54
의/JKG 117 51
ㄴ/ETM 106 43
여/EC 59 37
,/SP 88 35
- matrix는 dataframe과 다르게 colname 중복을 허용한다
연어 추출 I 단계: 공기어 추출/용례 (concordance)
- 방법 I:
node <- "/JKO"
index <- grep(node, Mors)
span <- vector()
for ( i in index){
span <- c(span, c((i-4):(i-1), (i+1):(i+4))) #JKO 양 옆 형태소 각각 4개씩 추출
}
span <- span[ span>0 & span<=length(Mors) ] #실제 Mors index에서 0보다 작거나 최대 length보다 높은 index 제외
crc <- Mors[ span ]
- 방법 II :
lapply사용
node <- "/JKO"
index <- grep(node, Mors)
span <- unlist(lapply( index, function(i){c((i-4):(i-1), (i+1):(i+4))}))
span <- span[ span>0 & span<=length(Mors) ]
crc <- Mors[span]
연어 추출 II 단계: 공기빈도 데이터프레임
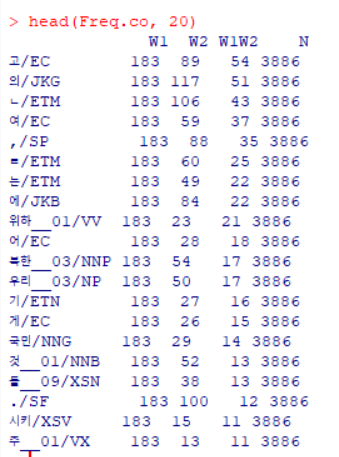
| 변수명 | 설명 |
|---|---|
| W1 | 중심어 총빈도 |
| W2 | 공기어 총빈도 |
| W1W2 | 공기빈도 |
| N | 텍스트 크기 |
- 방법 I:
Freq.span <- sort(table(crc), decreasing = T)
Freq.all <- table(Mors)
Freq.co <- data.frame( W1 = vector(), W2= vector(),
W1W2=vector(), N= vector() ) #initialize
n <- 1
for ( i in (1:length(Freq.span))){
Freq.co[n, ] <- c(length(index), # W1
Freq.all[names(Freq.all)==names(Freq.span)[i]], # W2
Freq.span[i], # W1W2
length(Mors)) # N
rownames(Freq.co)[n] <- names(Freq.span)[i]
n <- n + 1
}
- <code>Freq.all[names(Freq.all)==names(Freq.span)[i]]</code> 코드 이해
```R
> head(Freq.all)
Mors
%/SW (/SS )/SS ,/SP ./SF :/SP
3 1 1 88 100 1
> head(Freq.span)
crc
고/EC 의/JKG ㄴ/ETM 여/EC ,/SP ㄹ/ETM
54 51 43 37 35 25
```
- 예를 들어 names(Freq.span[3]) = <code>ㄴ/ETM</code>,
- Freq.all의 위치는 106이다 (??여기 조금 더 자세히 보기)
방법 II :
sapply로 간단하게 하기Freq.co <- data.frame( t(sapply(names(Freq.span), function(x){ c(length(index), Freq.all[x], Freq.span[x], length(Mors))}) )) colnames(Freq.co) <- c('W1', 'W2', 'W1W2', 'N')
연어 추출 III 단계: 연어 계산
대표적인 연어 추출 공식 \[t = \frac {f_{AB} - \frac{f_A \times f_B}{N}} {\sqrt{f_{AB}}}\] \[MI = log_2 \times \frac {f_{AB} \times N } {f_A \times f_B}\]
- \(N\) : 코퍼스/텍스트 크기
- \(F_{AB}\) : span내에서 두 어휘 A, B의 공기빈도
- \(F_A\) : 코퍼스/텍스트 전체에서 어휘 A의 빈도
- \(F_B\) : 코퍼스/텍스트 전체에서 어휘 B의 빈도
값이 클수록 연어 가능성이 높다
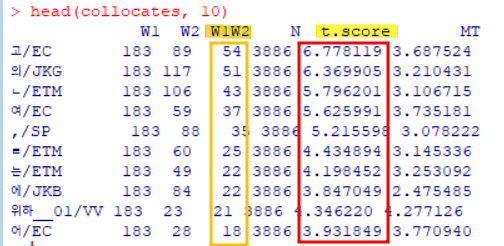
> collocates <- data.frame(Freq.co, t.score = (Freq.co$W1W2 - ((Freq.co$W1*Freq.co$W2)/Freq.co$N))/sqrt(Freq.co$W1W2), MT = log2((Freq.co$W1W2*Freq.co$N)/ (Freq.co$W1*Freq.co$W2)))t.score 내림차순 정렬
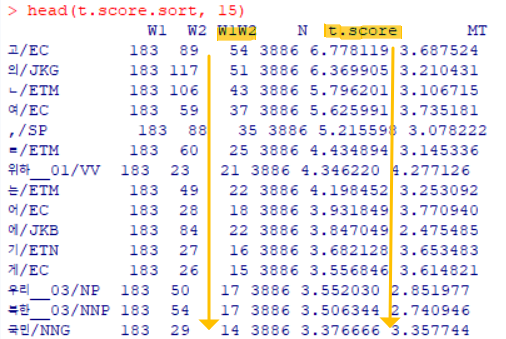
t.score.sort <- collocates[ order(collocates$t.score, decreasing = T), ]- 관찰 포인트: t score이 높으면 공기빈도 (W1W2)도 높을 가능성이 높다
MI 내림차순 정렬
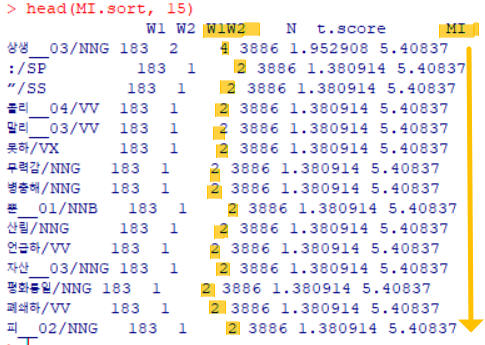
MI.sort <- collocates[ order(collocates$MI, decreasing = T), ]- 관찰 포인트: (단점) 공기빈도 낮은게 과대 반영됨
- 하지만 ‘을/를’ 주변의 function word가 아닌 content word를 많이 볼 수 있음
- 최소 공기빈도 제한
- MI 내림차순 보기 시 낮은 공기빈도 극복 -> 2 이상으로 제한하기
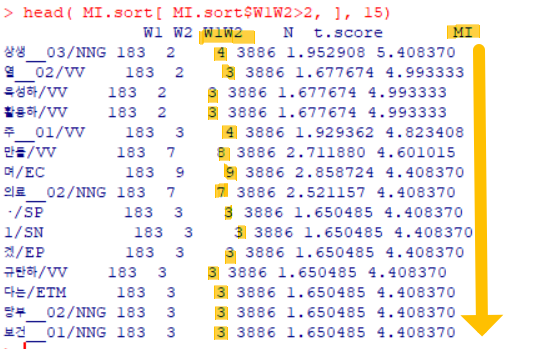
head( MI.sort[ MI.sort$W1W2>2, ], 15)unigram, bigram에서 못 찾는 정보를 찾을 수 있다
명사만 보기

더욱 경제적, 의료관련 단어들이 많이 사용됨(강조)을 볼 수 있다
정리
T Score : 고빈도 관찰에 좋으며 자주 사용됨- 단, unigram, bigram에서 이미 cover되었을 가능성이 높다
MI Score : 반복적인, 비슷한 단어들 여러번 사용 정황 포착 => 강조 범위를 찾는다- 저빈도 관찰에 좋다
연습문제
Obama 연설문에서 “we” 기준 bigram vs 연어분석 보기
- ‘we’ bigram의 안 좋은점 : 조동사와 결합 다수 (ex: we have, we can, we are …)
- 연어 분석이 필요해 보임
연습문제 #4:
- 10_Obama.txt에 대해 어휘 단위 파일로 불러와서 소문자 변환
- () 안의 지문 제거
- 어휘 앞뒤 문장부호 연쇄제거
- 벡터의 원소 중 빈문자열 제거
- 정규표현식 ‘\bwe\b’ 앞뒤 4개 어휘로 구성 벡터 (공기어 목록/용례) 만들기
- 공기어 빈도 데이터프레임 만들기
- 공기어 빈도 데이터프레임에 MI계산 컬럼 추가
- 공기빈도 3개 이상 & MI 내림차순 데이터 프레임 만들기
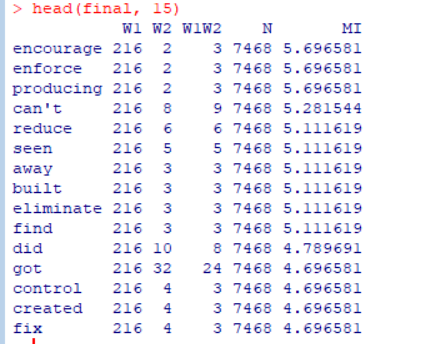
답
TEXT <- scan(file="10_Obama.txt", what="char", quote=NULL) text <- tolower(TEXT) text <- gsub('[(].+?[)]', '', text) text <- gsub('^[[:punct:]]+|[[:punct:]]+$', '', text) text <- text[ nchar(text) > 0] # 1단계: 공기어 목록 index <- grep('\\bwe\\b', text) span <- unlist(lapply(index, function(i){c((i-4):(i-1), (i+1):(i+4))})) span <- span[ span > 0 & span <= length(text)] crc <- text[span] #2단계 : 데이트프레임으로 변환 > text.span <- sort(table(crc), decreasing = T) > text.all <- table(text) > > text.co <- data.frame( t(sapply(names(text.span), + function(i){c(length(index), text.all[i], text.span[i], length(text))}))) > colnames(text.co) <- c('W1', 'W2', 'W1W2', 'N') # 3단계 : add MI score collocates <- data.frame(text.co, MI = log2((text.co$W1W2*text.co$N)/(text.co$W1*text.co$W2))) # 마무리: 공기빈도 3이상, MI 내림차순 정렬 > MI.sort <- collocates[ order(collocates$MI, decreasing = T), ] > final <- MI.sort[ MI.sort$W1W2 > 2, ]