04 Regular Expressions
in Notes / Dataanalytics / Datascience
- String Canonicalization
- Extracting data from text
- Advanced Regular Expressions Syntax
- Regular Expressions in Python
String Canonicalization
Canonicalize: Convert data that has more than one possible presentation into a standard form
A Joining Problem
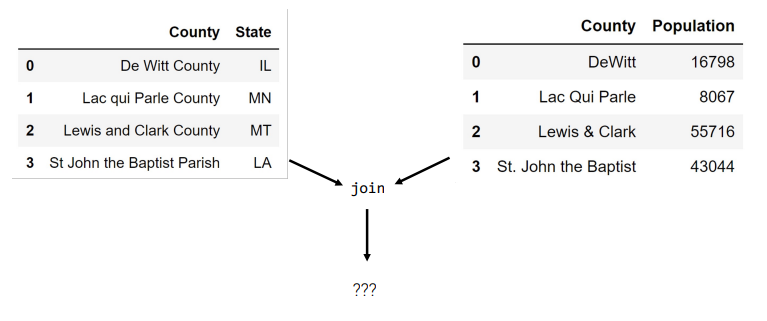
- useful codes:
- Replacement:
str.replace('&', 'and') - Deletion:
str.replace(' ', '') - Transformation:
str.lower()
- Replacement:
Extracting data from text
Date Information
169.237.46.168 - - [26/Jan/2014:10:47:58 -0800] "GET /stat141/Winter04/
HTTP/1.1" 200 2585 "http://anson.ucdavis.edu/courses/"
- how to get Date Information from the above log file
Better to use \(Regular\) \(Expression\) rather than scratch
import re pattern = r'\[(\d+)/(\w+)/(\d+):(\d+):(\d+):(\d+) (.+)\]' day, month, year, hour, minute, second, time_zone = re.search(pattern, text).groups()Formal Language : set of strings, typically described implicitly
-
"The set of all strings of length less than 10 & that contains a 'horse'"
-
- Regular Language : a formal language that can be described by a regular expression
-
`[0-9]{3}-[0-9]{2}-[0-9]{4}` - 3 of any digit, then a dash, then 2 of any digit, then a dash, then 4 of any digit.
text = "My social security number is 123-45-6789."; pattern = r"[0-9]{3}-[0-9]{2}-[0-9]{4}" re.findall(pattern, text)
-
Useful Site for testing Regex: Regex101
- Basic Operators
| operation | order | example | matches | does not match |
|---|---|---|---|---|
| concatenation | 3 | AABAAB | AABAAB | every other string |
| or | 4 | AA|BAAB | AA, BAAB | every other string |
| closure (zero or more) | 2 | AB*A | AA, ABBBBBBA | AB, ABABA |
| parenthesis | 1 | A(A|B)AAB | AAAAB, ABAAB | every other string |
(AB)*A | A, ABABABABA | AA ABBA |
Regex that matches `moon`, `moooon` (even `o`s except 0)
moo(oo)*n
Regex that matches `muun`, `muuuun`, `moon`, `moooon (even `o`s or `u`s except 0)
mo(u(uu)*|o(oo)*)n
- Expanded Regex Syntax
| operation | example | matches | does not match |
|---|---|---|---|
| any character (except newline) | .U.U.U. | CUMULUS, JUGULUM | SUCCUBUS, TUMULTUOUS |
| character class | [A-Za-z][az]* | word, Capitalized | camelCase, 4illegal |
| at least one | jo+hn | john, joooooohn | jhn, jjohn |
| zero or one | joh?n | jon john | any other string |
repeated exactly {a} times | j[aeiou]{3}hn | jaoehn,jooohn | jhn, jaeiouhn |
repeated from a to b times: {a,b} | j[ou]{1,2}hn | john, juohn | jhn, jooohn |
More Regular Expression Examples
regex matches does not match .*SPB.*RASPBERRY,CRISPBREADSUBSPACE,SUBSPECIES[0-9]{3}-[0-9]{2}-[0-9]{4}231-41-5121,573-57-1821231415121,57-3571821[a-z]+@([a-z]+\.)+(edu | com)horse@pizza.com,horse@pizza.food.comfrank_99@yahoo.com,hug@cs
Regex n for any lowercase string that has a repeated vowel
[a-z]*(aa|ee|ii|oo|uu)+[a-z]*
Regex n for any string that contains both a lowercase letter & number
(.*[a-z].*[0-9].*)|(.*[0-9].*[a-z].*)
Advanced Regular Expressions Syntax
- since RE is difficult to read, it is (sarcastically) called “write only language”
| operation | example | matches | does not match |
|---|---|---|---|
| built-in character classes | \w+, \d+ | fawef, 231231 | this person, 423 people |
| character class negation | [^a-z]+ | PEPPERS3982, 17211!@# | porch, CLAmS |
| escape character | cow\.com | cow.com | cowscom |
| beginning of line | ^ark | ark two, ark o ark | dark |
| end of line | ark$ | dark, ark o ark | ark two |
| lazy version of zero or more *? | 5.*?5 | 5005, 55 | 5005005 |
- escape character: can be thought of it as “take this next character literally”
Regex that matches anything inside of the angle brackets <>
`<.*?>`
Regular Expressions in Python
re.findall(pattern, text): return list of all matchestext = """My social security number is 456-76-4295 bro, or actually maybe it’s 456-67-4295.""" pattern = r"[0-9]{3}-[0-9]{2}-[0-9]{4}" m = re.findall(pattern, text) print(m)>>> ['456-76-4295', '456-67-4295']re.sub(pattern, repl, text): return text with all instances of pattern replaced by repl.text = '<div><td valign="top">Moo</td></div>' pattern = r"<[^>]+>" cleaned = re.sub(pattern, '', text) print(cleaned)>>> 'Moo'Raw strings in Python : strongly suggest using RAW STRINGS
- using
r" "instead of""or'' - Rough idea: Regular expressions and Python strings both use \ as an escape character
- Using non-raw strings leads to uglier regular expressions.
- using
RE Groups
- Parentheses specifies a so-called ‘group’
- regular expression matchers
ex: `re.findall` will return matches organized by groups (tuples, in Python)
s = """Observations: 03:04:53 - Horse awakens. 03:05:14 - Horse goes back to sleep.""" pattern = "(\d\d):(\d\d):(\d\d) - (.*)" matches = re.findall(pattern, s)>>> [('03', '04', '53', 'Horse awakens.'), ('03', '05', '14', 'Horse goes back to sleep.')]Practice Problem:
pattern = "YOUR REGEX HERE" matches = re.findall(pattern, log[0]) day, month, year = matches[0]Answer
”[(\d{2})/(\w{3})/(\d{4})”
Summary and other (alternative) tools
| basic python | re | pandas |
|---|---|---|
re.findall | df.str.findall | |
str.replace | re.sub | df.str.replace |
str.split | re.split | df.str.split |
'ab' in str | re.search | df.str.contain |
len(str) | df.str.len | |
str[1:4] | df.str[1:4] |