Convolutional Neural Network
in Notes / Artificialintelligence / Introductiontoai
DAY 10
Introduction

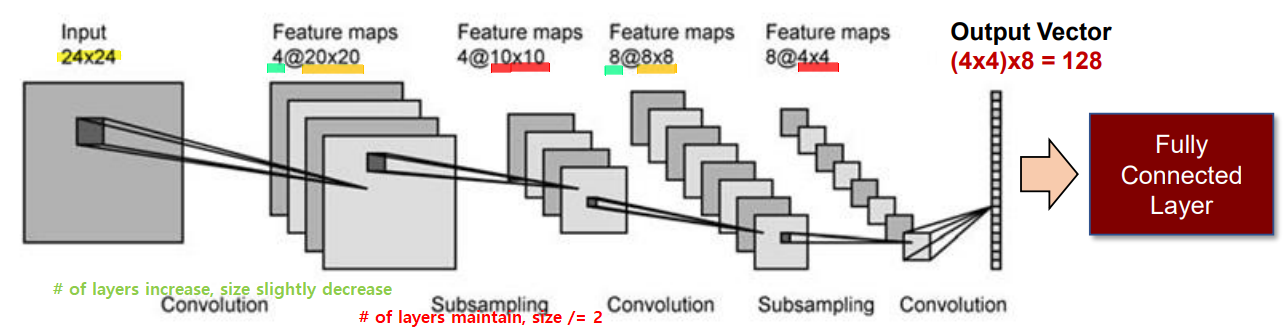
CNN - CNN - POOL repeated, Softmax at the end
\(Wx + b\) -> \(Y = w_1x_1 + w_2x_2 + \cdots + w_nx_n + b\)
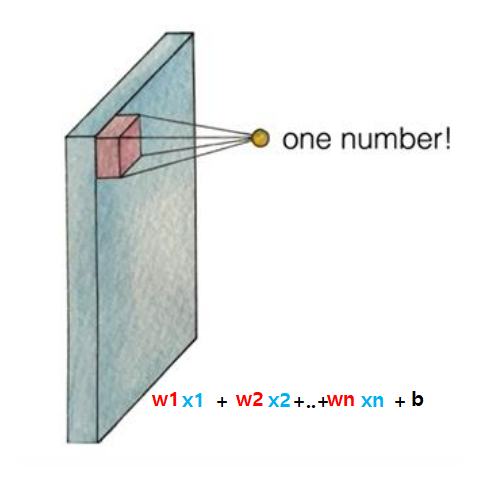
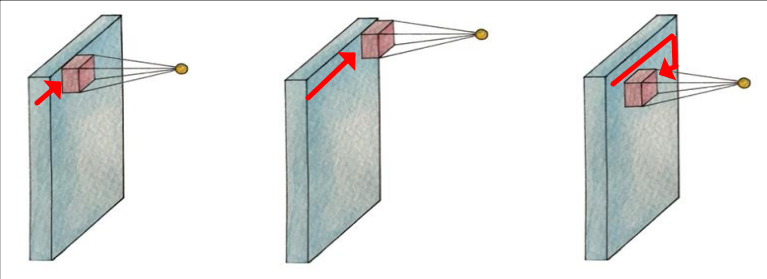
- filter can be computed into that one number (dot) = \(activationFunction( W_x + b)\) (기본적인 딥러닝)
- those dots (filter) become activation map (aka feature map)
filter 개수에 따라 map 개수 달라짐
model.add(Dense(256, activation='relu'))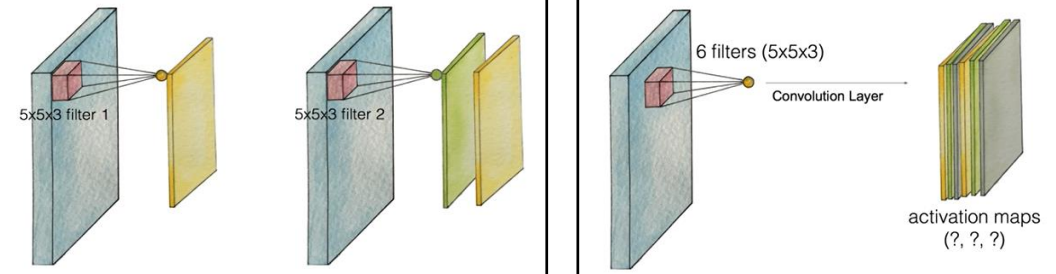
Example
- Image Size: 7 * 7
- Filter Size : 3 * 3
Strides (step - size of filter moving)
- stride = 1 -> 5 * 5 = 25 times
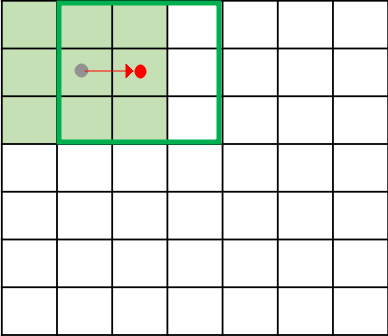
- stride = 2 -> 3 * 3 = 9 times
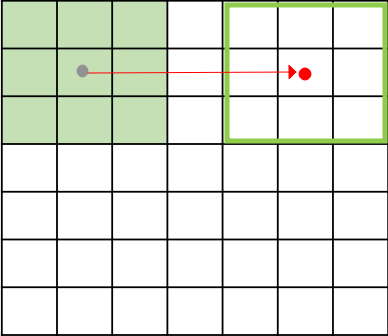
- stride = 1 -> 5 * 5 = 25 times
- Larger strides loose information, however, the value degrades as well.
Padding
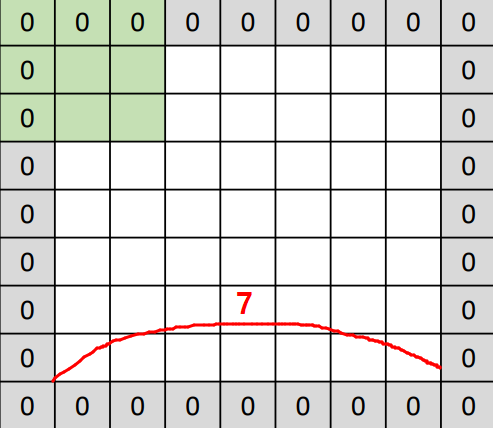
- to maintain the actual size of the input (7 * 7) instead of (5 * 5) at most, apply padding around the image => (9 * 9)
- When Stride = 1 on a (9 * 9) padded image => (7 * 7) is possible.
- 0 is used to eliminate \(W_1x_1, W_2x_2, ...\)
Pooling (or Sampling)
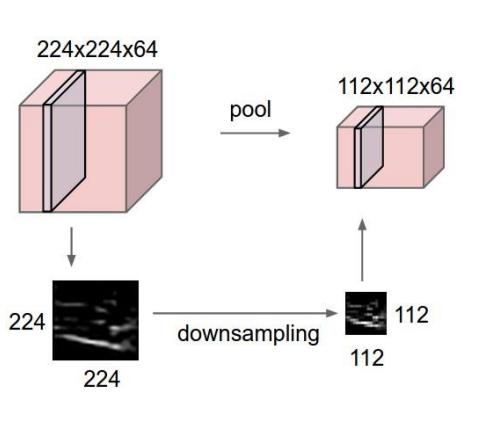
- What it is: compressing images
- Why we need it: avoid exploding amount of images and sizes when going through hidden layers
- When we do it : in between CNNs
Max Pooling Concept
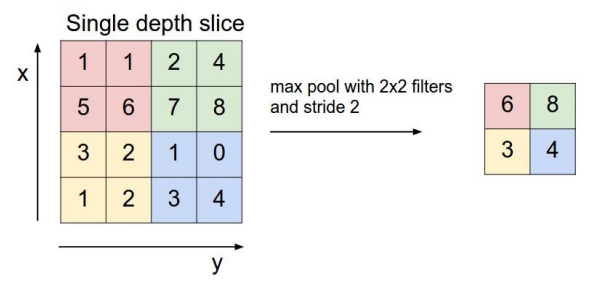
- max pooling: get largest slice => BEST (not proven, but 경험적으로)
- average pooling: get mean slice
min pooling: get samllest slice -> may converge to 0 => BAD
- usually use 2 x 2 filters with stride = 2
CNN: Example
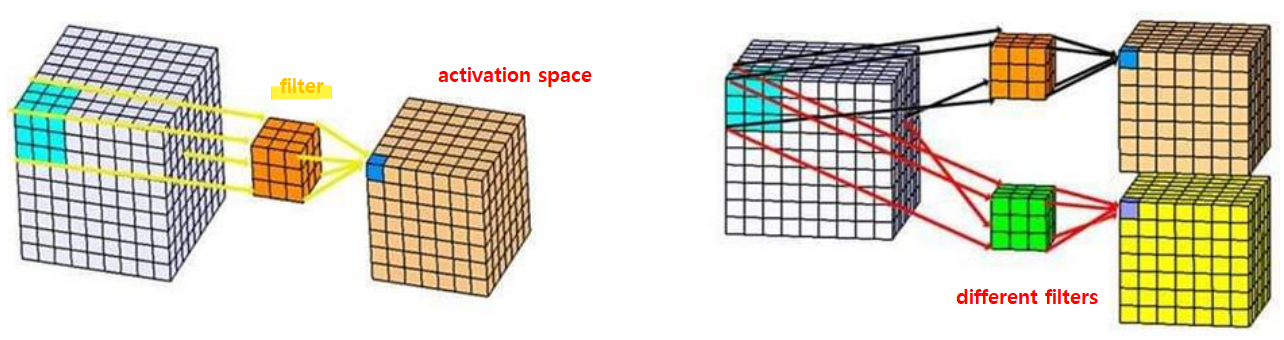
- different filters (ex: specialized for finding “car”) => several output (inputs that are pre-filtered before other training)
CNN Implementaion (Keras)
MNIST
from keras.models import Sequential from keras.layers import Dense, Conv2D, pooling, Flatten from keras.datasets import mnist from keras.utils import np_utils (train_images, train_labels), (test_images, test_labels) = mnist.load_data() train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')/255.0 test_images = test_images.reshape(test_images.shape[0], 28, 28, 1).astype('float32')/255.0 train_labels = np_utils.to_categorical(train_labels) test_labels = np_utils.to_categorical(test_labels) model = Sequential() # SIZE : 28 - by 28 (number: 1) # number of filter # padding YES model.add(Conv2D(32, (3,3), padding = 'same', strides=(1,1), activation='relu', input_shape=(28,28,1))) # filter size # compute convolution 1 by 1 => no size reduction # => SIZE : 28 - by 28 (number: 32) model.add(pooling.MaxPooling2D(pool_size=(2,2))) # => SIZE : 14 - by 14 (number: 32) # 32개 받아서 64로 내보내기 model.add(Conv2D(64, (3,3), padding = 'same', strides=(1,1), activation='relu')) # => SIZE : 14 - by 14 (number: 64) model.add(pooling.MaxPooling2D(pool_size=(2,2))) # => SIZE : 7 - by 7 (number: 64) model.add(Flatten()) model.add(Dense(10, activation='softmax')) # W: 784 by 10 ; b : 10 model.compile(loss = 'categorical_crossentropy', optimizer = 'sgd', metrics=['accuracy']) model.fit(train_images, train_labels, epochs = 5, batch_size=32, verbose = 1) cost, accuracy = model.evaluate(test_images, test_labels) print('Accuracy: ', accuracy) model.summary()
OUTPUT
Epoch 1/5
1875/1875 [==============================] - 75s 40ms/step - loss: 0.5400 - accuracy: 0.8451
Epoch 2/5
1875/1875 [==============================] - 73s 39ms/step - loss: 0.1643 - accuracy: 0.9510
Epoch 3/5
1875/1875 [==============================] - 73s 39ms/step - loss: 0.1121 - accuracy: 0.9670
Epoch 4/5
1875/1875 [==============================] - 75s 40ms/step - loss: 0.0898 - accuracy: 0.9736
Epoch 5/5
1875/1875 [==============================] - 74s 39ms/step - loss: 0.0762 - accuracy: 0.9773
313/313 [==============================] - 4s 13ms/step - loss: 0.0749 - accuracy: 0.9775
Accuracy: 0.9775000214576721
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_7 (Conv2D) (None, 28, 28, 32) 320
max_pooling2d_6 (MaxPooling (None, 14, 14, 32) 0
2D)
conv2d_8 (Conv2D) (None, 14, 14, 64) 18496
max_pooling2d_7 (MaxPooling (None, 7, 7, 64) 0
2D)
flatten_3 (Flatten) (None, 3136) 0
dense_3 (Dense) (None, 10) 31370
=================================================================
Total params: 50,186
Trainable params: 50,186
Non-trainable params: 0
_________________________________________________________________
Other Datasets
MNIST  | CIFAR-10, 100  | IMAGENET  | |
|---|---|---|---|
| Num Channel | 1 (Gray Scale) | 3 (RGB) | 3 (RGB) |
| Num Calsses | 10 (0~9) | 10, 100 | 1000 |
| Resolution | 28 * 28 | 32 * 32 | 256 * 256 (too high, supercomputers ONLY) |
| Num Training Set (updated constantly) | 60,000 | 50,000 | 200,000 |
CIFAR-10 (difference from MNIST data
#commented)from keras.layers import Dense, Conv2D, pooling, Flatten from keras.datasets import cifar10 # CIFAR 10 from keras.utils import np_utils (train_images, train_labels), (test_images, test_labels) = cifar10.load_data() train_images = train_images.reshape(train_images.shape[0], 32, 32, 3).astype('float32')/255.0 #SIZE 변경 (3 = RGB) test_images = test_images.reshape(test_images.shape[0], 32, 32, 3).astype('float32')/255.0 #SIZE 변경 (3 = RGB) train_labels = np_utils.to_categorical(train_labels) test_labels = np_utils.to_categorical(test_labels) model = Sequential() model.add(Conv2D(32, (3,3), padding = 'same', strides=(1,1), activation='relu', input_shape=(32, 32, 3))) # SIZE 변경 model.add(pooling.MaxPooling2D(pool_size=(2,2))) model.add(Conv2D(64, (3,3), padding = 'same', strides=(1,1), activation='relu')) model.add(pooling.MaxPooling2D(pool_size=(2,2))) model.add(Flatten()) model.add(Dense(10, activation='softmax')) model.compile(loss = 'categorical_crossentropy', optimizer = 'sgd', metrics=['accuracy']) model.fit(train_images, train_labels, epochs = 5, batch_size=32, verbose = 1) cost, accuracy = model.evaluate(test_images, test_labels) print('Accuracy: ', accuracy) model.summary()
OUTPUT
- ACCURACY PRETTY LOW :
56% SIZE도 훨씬 크고, Color 도 RGB임
Epoch 1/5 1563/1563 [==============================] - 100s 64ms/step - loss: 1.9522 - accuracy: 0.3068 Epoch 2/5 1563/1563 [==============================] - 90s 58ms/step - loss: 1.5946 - accuracy: 0.4371 Epoch 3/5 1563/1563 [==============================] - 89s 57ms/step - loss: 1.4124 - accuracy: 0.4997 Epoch 4/5 1563/1563 [==============================] - 91s 58ms/step - loss: 1.3086 - accuracy: 0.5400 Epoch 5/5 1563/1563 [==============================] - 89s 57ms/step - loss: 1.2334 - accuracy: 0.5692 313/313 [==============================] - 5s 17ms/step - loss: 1.2337 - accuracy: 0.5565 Accuracy: 0.5565000176429749 Model: "sequential_5" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_9 (Conv2D) (None, 32, 32, 32) 896 max_pooling2d_8 (MaxPooling (None, 16, 16, 32) 0 2D) conv2d_10 (Conv2D) (None, 16, 16, 64) 18496 max_pooling2d_9 (MaxPooling (None, 8, 8, 64) 0 2D) flatten_4 (Flatten) (None, 4096) 0 dense_4 (Dense) (None, 10) 40970 ================================================================= Total params: 60,362 Trainable params: 60,362 Non-trainable params: 0 _________________________________________________________________
Viewing DataSet Images
- CIFAR
from keras.datasets import cifar10 # CIFAR 10 from matplotlib import pyplot as plt (train_images, train_labels), (test_images, test_labels) = cifar10.load_data() plt.imshow(train_images[0]) plt.show() CIFAR10 and MNIST
from keras.datasets import cifar10, mnist from matplotlib import pyplot as plt (train_cifar10_images, train_cifar10_labels), (test_cifar10_images, test_cifar10_labels) = cifar10.load_data() (train_mnist_images, train_mnist_labels), (test_mnist_images, test_mnist_labels) = mnist.load_data() plt.imshow(train_cifar10_images[0]) plt.show() plt.imshow(train_mnist_images[0]) plt.show()OUTPUT IMAGES
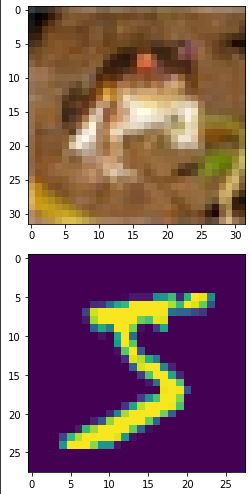
- MNIST is much cleaner and simple (especially for non-experts)
- (참고) RNN Skipped